能力困境 传统提示词方法:
Token爆炸成本高:每次请求携带完整上下文
模型幻觉风险剧增:信息过载导致模型注意力分散
维护困难:数千行代码难以版本控制
AgentSkills方法:将能力拆解为独立的技能文件夹,按需动态加载,实现精准调用
上下文纯净:只加载必要的技能信息,Token消耗降低80%以上
降低幻觉:精准匹配的技能上下文显著提升模型输出准确性
支持协作:Git版本控制友好
Agent Skill
扩展Agent能力
Tool use 工具调用
MCP
提供的是 工具能力,一次性加载所有Agent
问题
如何快准狠调用工具(精度)
Token 消耗
上下文爆炸
Skill
渐进式披露
三层加载
元数据(Agent启动时候加载一次)
技能(可重复加载)
调用工具)
解决痛点
开发范式
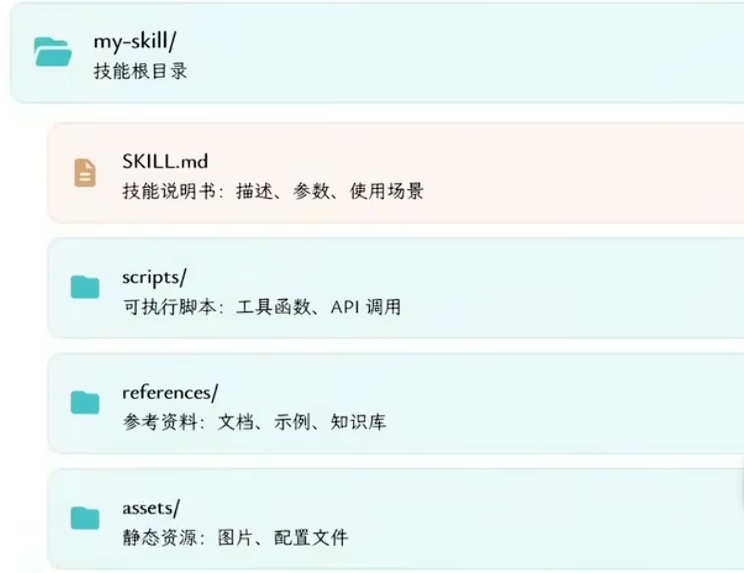
AgentSkills核心机制 Skill文件夹结构 核心机制:渐进式披露 Progressive Disclosure - 动态上下文加载策略
Discovery发现:仅读取技能元数据(名称、描述、标签),Token消耗极低,快速匹配用户意图
Activation激活:意图匹配后,动态注入该技能的完整指令(SKILL.md+必要参数),精准加载
Execution执行:根据需要调用脚本(script/)或检索参考资料(references/),完成具体任务
意图识别→技能筛选→动态加载→执行输出
核心架构公式与演示 实现原理 系统启动准备
1 2 3 4 5 graph TD A[启动程序] --> B[加载配置] B --> C[扫描技能目录] C --> D[预连接数据库] D --> E[初始化千问模型]
用户请求处理全流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 sequenceDiagram participant 用户 participant 代理核心 participant 千问模型 participant 技能脚本 participant 外部服务 用户->>代理核心: "分析北京用户订单,生成Python图表代码" 代理核心->>千问模型: 意图识别请求 千问模型-->>代理核心: ["query_writer", "codewhisperer-integration"] loop 逐个执行技能 代理核心->>技能脚本: 激活query_writer 技能脚本->>数据库: 执行JOIN查询 数据库-->>技能脚本: 返回订单数据 技能脚本-->>代理核心: {data: [...]} 代理核心->>技能脚本: 激活codewhisperer 技能脚本->>外部服务: 调用本地CAW 外部服务-->>技能脚本: 返回Python代码 end 代理核心->>千问模型: 整合结果生成自然语言 千问模型-->>用户: "已找到3笔订单,总金额¥42,800,代码如下:..."
具体实现案例流程(以“千问模型”为例) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 flowchart LR %% 系统启动阶段(左→右) START([程序启动]) --> CONFIG[加载AGENTS.md配置] CONFIG --> SCAN[扫描.skills/目录] SCAN --> DISCOVER{发现技能?} DISCOVER -- 是 --> PARSE[解析SKILL.md元数据] DISCOVER -- 否 --> ERROR[报错:未找到技能] PARSE --> INIT_DB[初始化sql_tools] INIT_DB --> INIT_QWEN[配置千问API密钥] %% 请求处理阶段(垂直向下) INIT_QWEN --> INPUT[/用户输入/] INPUT --> INTENT[千问意图识别] INTENT --> MATCH{需调用技能?} MATCH -- 是 --> ACTIVATE[按顺序激活技能] MATCH -- 否 --> DIRECT[直接千问回答] ACTIVATE --> EXECUTE[执行scripts/工具] EXECUTE --> RESULT[返回结构化数据] RESULT --> AGGREGATE[千问整合结果] AGGREGATE --> OUTPUT[(多模态输出)] %% 循环与异常处理 OUTPUT --> INPUT ERROR -->|人工修复| CONFIG DIRECT --> OUTPUT %% 样式定义(紧凑布局) classDef startEnd fill:#f9f,stroke:#333,stroke-width:1px; classDef process fill:#eef,stroke:#33f,stroke-width:1px; classDef decision fill:#fcc,stroke:#f63,stroke-width:1px; classDef io fill:#dfd,stroke:#393,stroke-width:1px; class START,OUTPUT startEnd class CONFIG,SCAN,PARSE,INIT_DB,INIT_QWEN,ACTIVATE,EXECUTE,RESULT,AGGREGATE process class DISCOVER,MATCH decision class INPUT,ERROR io %% 布局优化 linkStyle default stroke:#666,stroke-width:1.5px; style START width:80px,height:40px; style OUTPUT width:100px,height:40px;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 flowchart LR %% 系统启动阶段(顶部横向) subgraph INIT ["系统初始化"] direction LR START([🚀程序启动]) --> MODEL[加载大模型或者初始化大模型] MODEL[加载大模型或者初始化大模型] --> CONFIG[📄加载AGENTS.md] CONFIG --> SCAN[🔍扫描.skills/目录] SCAN --> DISCOVER{❓发现技能?} DISCOVER -- 是 --> PARSE[📋解析SKILL.md] DISCOVER -- 否 --> ERROR[❌报错:未找到技能] ERROR -.->|人工修复| CONFIG end INIT -->|初始化完成| PROCESS %% 请求处理阶段(中部垂直+横向混合) subgraph PROCESS ["请求处理流程"] direction TB INPUT[/💬用户输入/] --> INTENT[🤖千问意图识别] INTENT --> MATCH{🎯需调用技能?} %% 横向分支 MATCH -- 是 --> ACTIVATE[⚡按顺序激活技能] MATCH -- 否 --> DIRECT[📝直接千问回答] ACTIVATE --> EXECUTE[🛠️ 执行scripts/工具] EXECUTE --> RESULT[📊返回结构化数据] RESULT --> AGGREGATE[🔗千问整合结果] AGGREGATE --> OUTPUT[(📤多模态输出)] end %% 循环连接(底部) OUTPUT --> INPUT %% 样式美化(通过classDef和style) classDef startEnd fill:#FFD1DC,stroke:#FF69B4,stroke-width:2px,color:#333; classDef process fill:#E0F7FA,stroke:#00BCD4,stroke-width:1.5px; classDef decision fill:#FFF9C4,stroke:#FFC107,stroke-width:2px; classDef io fill:#C8E6C9,stroke:#4CAF50,stroke-width:1.5px; classDef error fill:#FFEBEE,stroke:#F44336,stroke-width:2px; class START,OUTPUT startEnd class CONFIG,SCAN,PARSE,INIT_DB,INIT_QWEN,ACTIVATE,EXECUTE,RESULT,AGGREGATE process class DISCOVER,MATCH decision class INPUT,DIRECT io class ERROR error %% 节点尺寸和间距调整 style START width:100px, height:60px; style OUTPUT width:120px, height:60px; linkStyle default stroke:#666, stroke-width:2px;
工作流落地 属于具体应用