[toc]
关于Idea中的Maven和Gradle中jdk版本
| 层次 | 在哪里设置 | 主要影响什么 | 是否直接决定最终编译/运行 JDK | 备注 |
|---|---|---|---|---|
| IDEA 项目层 | Project Structure -> Project SDK |
IDEA 的项目模型、代码提示、部分本地运行配置 | 一般不直接决定 Gradle 项目的最终构建 JDK | 更偏 IDE 层 |
| IDEA 语法层 | Project Structure -> Language level |
编辑器语法检查、补全、部分 IDE 编译设置 | 一般不直接决定 Gradle 的最终构建 JDK | 更偏“能不能写这种语法” |
| Gradle 进程层(IDEA 外层) | Settings -> Gradle -> Gradle JVM |
IDEA 用哪个 JVM 启动 Gradle、导入项目、执行 Gradle task | 会影响,但若配置了 Toolchain,常常不是最终任务 JDK | 决定 Gradle 进程跑在哪个 JDK 上 |
| Gradle 进程层(Gradle 内层) | gradle.properties 中 org.gradle.java.home |
指定这个 Gradle build/Daemon 使用哪个 JDK 运行 | 会影响,但若配置了 Toolchain,通常也不是最终任务 JDK | 相当于强行指定 Gradle 自己跑在哪个 JDK 上 |
| Gradle 任务层 | build.gradle 里的 toolchain |
compileJava、test、javadoc、JavaExec 等任务实际使用的 JDK |
通常最关键 | 有 Toolchain 时,任务通常按它走 |
| Gradle 兼容层 | sourceCompatibility / targetCompatibility / --release |
指定源码级别、目标字节码级别、API 兼容级别 | 会影响编译结果,但不等于指定“Gradle 自己运行的 JDK” | 和 Toolchain 不是一回事 |
| Maven 进程层 | IDEA 里的 Maven Runner JRE / 系统 JAVA_HOME |
Maven 这个程序本身跑在哪个 JDK 上 | 会影响,但若配置了 Maven Toolchains,也未必是最终编译 JDK | |
| Maven 任务层 | pom.xml 里的 compiler plugin、toolchains 等 |
Maven 编译/测试任务实际使用的 JDK | 通常是最关键的 |
Idea中Maven、Gradle项目的三种网络代理方式
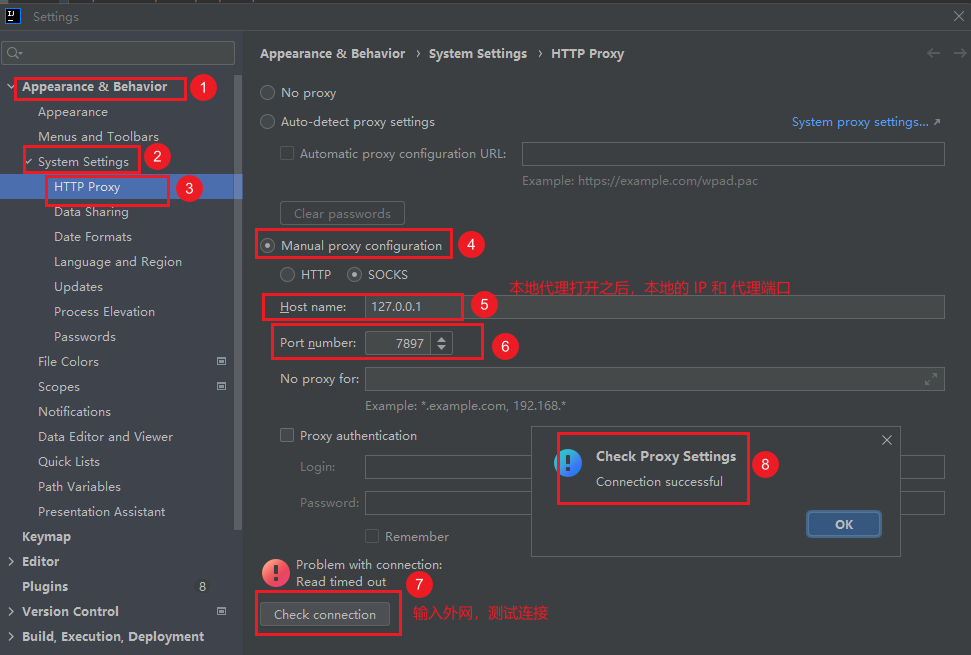
方式一:配置Idea(推荐)
方式二:Gradle项目
①全局(不推荐)
配置~/.gradle/gradle.properties文件
1 | =127.0.0.1 |
②项目级(推荐)
配置``gradle.properties`文件
1 | =127.0.0.1 |
方式三:Maven项目
①全局(不推荐)
配置~/.m2/setting.xml文件
1 | <settings> |
Spring中的IOC
Bean生命周期概览
BeanFactory 定义了完整的 Bean 生命周期回调顺序
1 | //初始化阶段: |
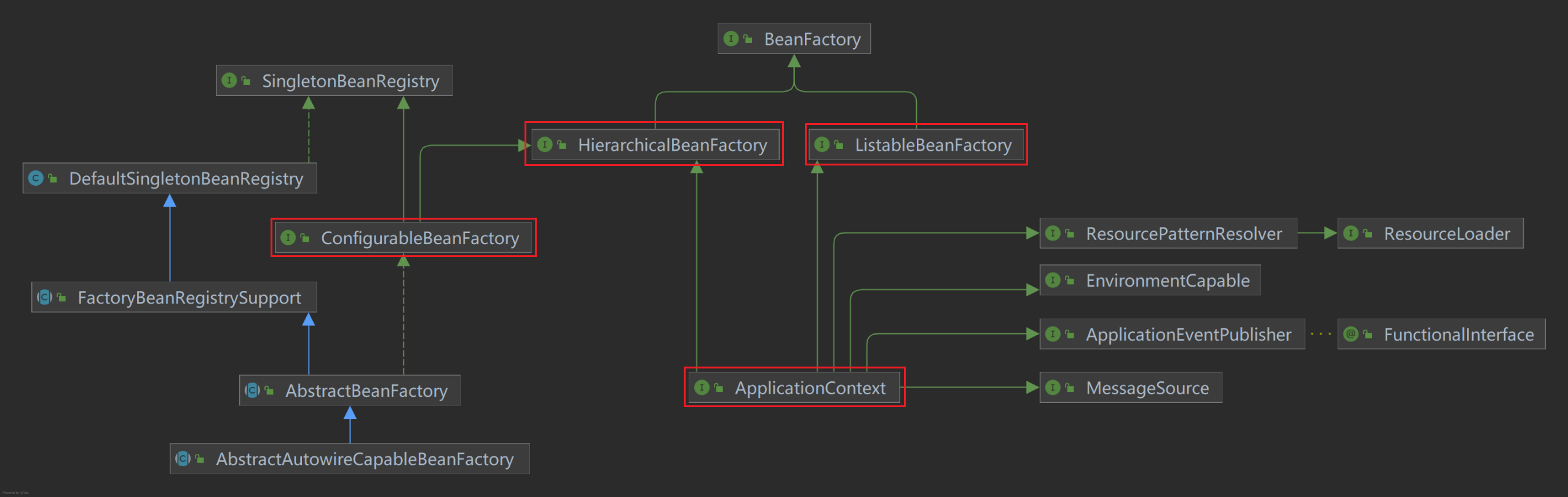
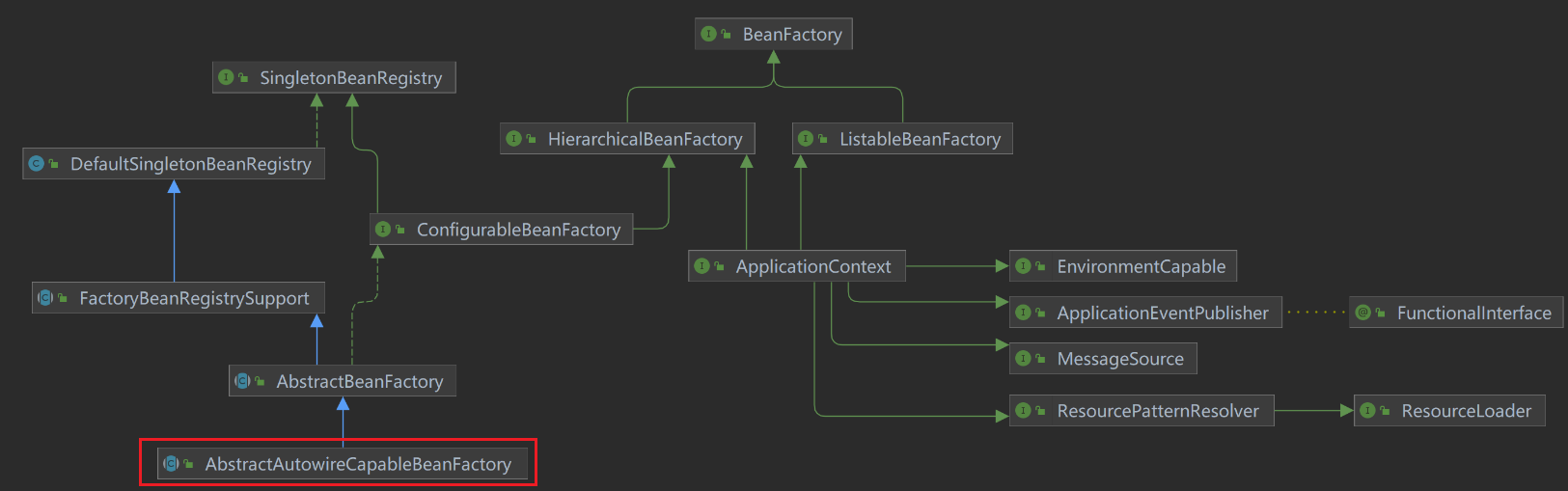
BeanFactory 接口家族
应用组件的中央注册表,并集中配置应用组件(例如,不再需要单个对象读取属性文件)
分三类:Listable、Configurable、ApplicationContext
BeanFactory
├─ ListableBeanFactory ← 能列举
├─ HierarchicalBeanFactory ← 有层级
│ └─ ConfigurableBeanFactory ← 可配置
│ └─ ConfigurableListableBeanFactory ← 可配置+可列举
└─ ApplicationContext ← 应用级(组合多个接口)
├─ ConfigurableApplicationContext
└─ WebApplicationContext
| 维度 | ListableBeanFactory | HierarchicalBeanFactory | ConfigurableBeanFactory | ApplicationContext |
|---|---|---|---|---|
| 核心职责 | 批量查询 Bean | 支持父子容器层级关系 | 配置容器本身 | 企业级功能整合 |
| 使用场景 | 查找某类型的所有 Bean | 子容器找不到 Bean 时,会委托给父容器 | 框架内部配置(类加载器、类型转换、后置处理器等) | 实际应用开发 |
| 关键方法 | getBeansOfType() |
getParentBeanFactory() |
addBeanPostProcessor() |
继承的所有接口 |
| 面向用户 | 应用开发者 | 框架开发者 | 应用开发者 | |
| 典型实现 | DefaultListableBeanFactory |
AbstractBeanFactory |
ClassPathXmlApplicationContext |
|
| 关键参数 | allowEagerInit允许热切初始化,(默认false) |
1 | public interface ApplicationContext extends |
思考
ListableBeanFactory
- 看完所有方法,理解”批量查询”的概念
- 重点理解 getBeansOfType() 的两个 boolean 参数
- 思考:为什么要有 allowEagerInit 这个参数?
ConfigurableBeanFactory
- 按我上面的分组阅读(类加载器、类型转换、后置处理器等)
- 重点关注 BeanPostProcessor 相关方法
- 思考:为什么这是框架内部用的接口?
ApplicationContext
- 看它继承了哪些接口
- 逐个查看父接口(MessageSource、ApplicationEventPublisher 等)
- 对比:ApplicationContext vs BeanFactory 的区别
两个getSingleton
getSingleton(String beanName, boolean allowEarlyReference)
源码理解
1 | /** |
思考
为什么在
try之前已经有获取锁操作,而try中还要依次从一、二、三级缓存获取对象?
防止锁前到锁内这段时间发生状态变化
保证“加锁后视图”是最新状态
举例:
A 进入
getSingleton,准备创建B 在别的路径里已经完成初始化并调用
addSingletonA 现在拿到锁(如果不重新检查一级缓存,A可能会重复创建对象)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
title 相同路径下,A在B释放锁后加锁重新检查缓存
dateFormat HH:mm:ss
axisFormat %H:%M:%S
section 线程A(当前 getSingleton 路径)
锁外检查未命中 :a1, 00:00:01, 1s
即将 tryLock :a2, 00:00:02, 1s
tryLock 成功 :a2, 00:00:07, 1s
锁内重新检查一二三级缓存 :a3, 00:00:08, 1s
返回最新可见对象,释放 singletonLock :a4, 00:00:09, 2s
section 线程B(当前 getSingleton 路径)
锁外检查未命中 :a1, 00:00:01, 1s
tryLock 成功 :a2, 00:00:03, 1s
锁内处理缓存逻辑(初始化对象系列工作) :b2, 00:00:04, 2s
释放 singletonLock :a5, 00:00:06, 1s
2
3
4
5
6
7
8
9
10
11
12
13
14
15
title 不同路径无锁修改缓存,A加锁后重新检查缓存
dateFormat HH:mm:ss
axisFormat %H:%M:%S
section 线程A(当前 getSingleton 路径)
锁外检查未命中 :a1, 00:00:01, 1s
tryLock 成功 :a2, 00:00:02, 1s
锁内重新检查一二三级缓存 :a3, 00:00:06, 2s
返回最新可见对象 :a4, 00:00:08, 1s
释放 singletonLock :a5, 00:00:09, 1s
section 线程B(不同路径,不加这把锁)
修改缓存状态 :b1, 00:00:03, 1s
可能放入一级缓存或调整二/三级缓存 :b2, 00:00:04, 2s为什么最后需要判断
this.singletonFactories.remove(beanName) != null,为什么从一级缓存中查询,而不一次先查二级再查一级缓存?
获取到的
factory可能已经被移除了,可能是另一个线程已经完成初始化了,或者已经通过adSingleton放入一级缓存了经过情况推理,如果三级缓存中
remove失败,不会出现在earlySingletonObjects的情况,所以只能从一级缓存中查询(remove成功时,二级缓存是当前线程发布early reference的位置;remove失败时,说明当前线程已经不能发布early reference,因此不再沿着二级缓存这条early reference路线走,而是直接回到一级缓存查最终对象。)举例:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
title 不同路径无锁修改缓存,A的remove失败并回退到一级缓存
dateFormat HH:mm:ss
axisFormat %H:%M:%S
section 线程A(当前 getSingleton 路径)
tryLock 成功 :a1, 00:00:01, 1s
获取 singletonFactory :a2, 00:00:02, 1s
调用 factory.getObject :a3, 00:00:03, 2s
remove 失败 :a4, 00:00:05, 1s
从一级缓存重新获取对象 :a5, 00:00:06, 1s
释放 singletonLock :a6, 00:00:07, 1s
section 线程B(不同路径,不加这把锁)
放入一级缓存 :b1, 00:00:03, 1s
清理三级缓存 :b2, 00:00:04, 1s本代码块中虽然加锁了,但是有一个重点理解:锁只保护这段代码,不能回溯过去,同时也不能阻止别的路径修改缓存;所以锁内逻辑是,防御性确认当前状态是否仍然有效

getSingleton(String beanName, ObjectFactory<?> singletonFactory)
源码理解
1 | /** |
思考
singletonLock是什么锁?
- 是某个
BeanFactory内部用于保护singleton注册表的公共锁,可以近似理解为“一个容器一把单例锁”,不是单个Bean的锁isCurrentThreadAllowedToHoldSingletonLock()返回值三种情况处理
true:允许持有singletonLock,但也允许tryLock失败后走宽松fallbackfalse:明确不允许持有singletonLock,强制走宽松fallbacknull:没有特殊指示,走传统行为,必须完整持有singletonLock
获取Bean:AbstractBeanFactory.doGetBean()
涉及类
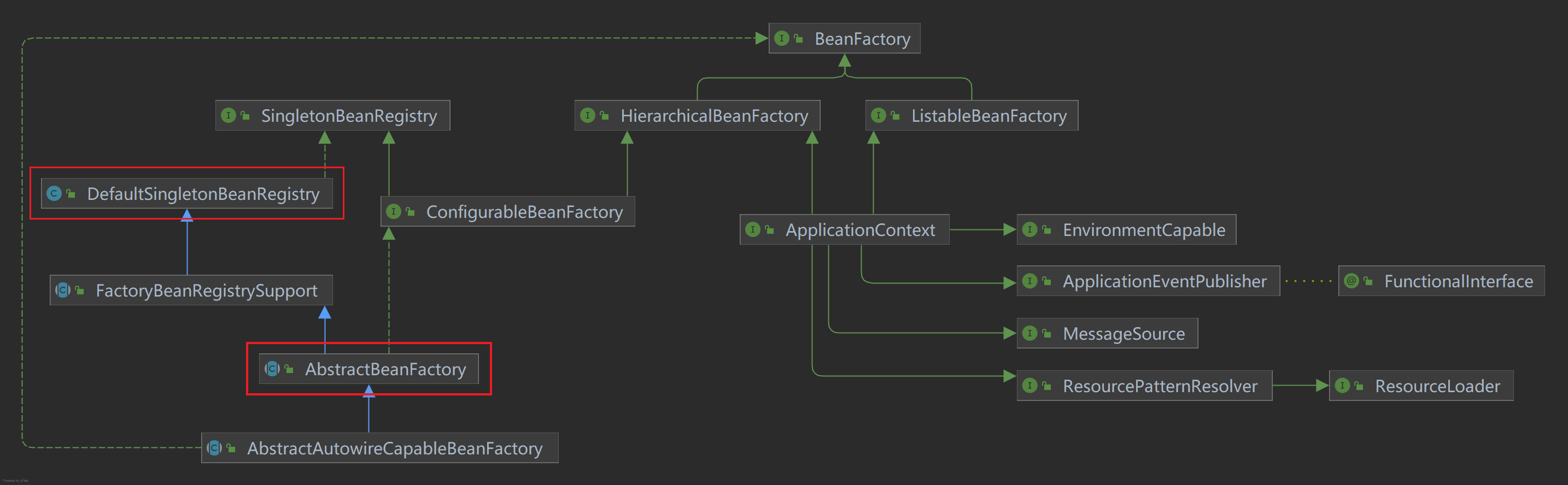
流程图
源码理解
1 | /** |
思考
为什么单例能解决循环依赖,而
prototype不能?
- 因为点哪里可以提前暴漏
early reference,prototype每次都是新对象,没有缓存支持为什么在父容器委托机制中,委托时会多出几种获取Bean的方式,比如根据
args创建Bean、根据期望类型获取Bean
- 当前容器自己处理时,看起来不需要区分
args、requiredType,是因为当前已经在doGetBean(...)这个统一入口里了;在当前容器内部,所有getBean调用最终都会汇总到同一个方法,所以当前容器继续往下执行时,不需要再区分调用者最初是:getBean(name)、getBean(name, requiredType)、getBean(name, args)- 但委托给父容器时,父容器未必暴露
doGetBean(...),所以只能根据参数情况选择不同的getBean(...)重载方法。
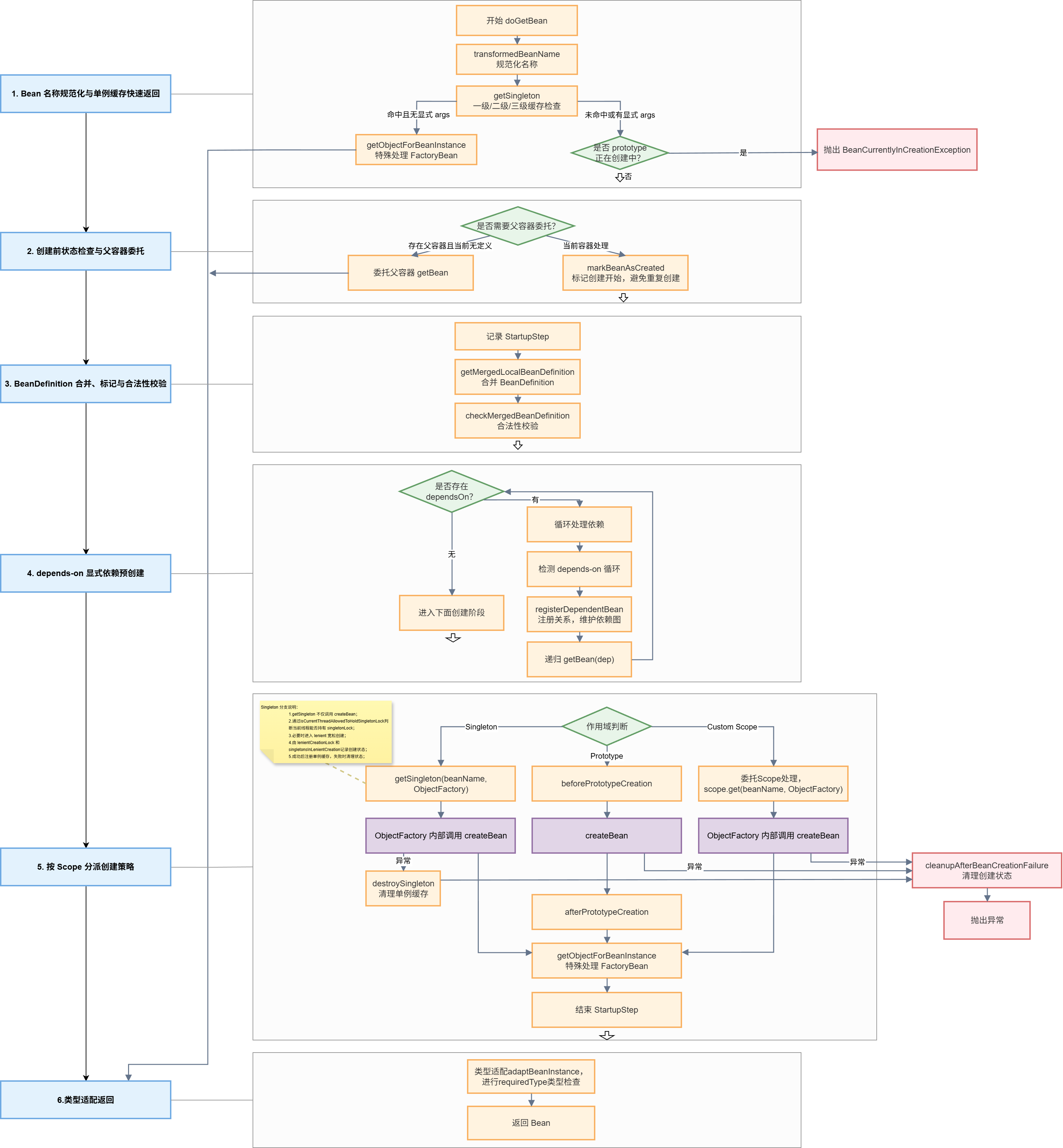
StartupStep beanCreation后紧接的代码块做了什么?
- 记录性能埋点
- 合并 BeanDefinition
- 检查合法性
- 处理 dependsOn
- 根据 scope 选择创建策略
- 单例使用三级缓存支持循环依赖
- 执行完整生命周期(createBean)
- 处理 AOP 代理
- 清理异常状态
- 类型适配并返回
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
A[1. 记录性能埋点] --> B[2. 合并 BeanDefinition]
B --> C[3. 检查合法性]
C --> D[4. 处理 dependsOn]
D --> E[5. 根据 scope 选择创建策略]
E --> F[6. 单例使用三级缓存支持循环依赖]
F --> G[7. 执行完整生命周期 createBean]
G --> H[8. 处理 AOP 代理]
H --> I[9. 清理异常状态]
I --> J[10. 类型适配并返回]
classDef process fill:#EAF3FF,stroke:#2F80ED,stroke-width:1.5px,color:#1B365D,rx:8,ry:8;
classDef key fill:#F3E8FF,stroke:#8B5CF6,stroke-width:1.5px,color:#3B0764,rx:8,ry:8;
classDef final fill:#E8F5E9,stroke:#43A047,stroke-width:1.5px,color:#1B5E20,rx:8,ry:8;
class A,B,C,D,E,I process;
class F,G,H key;
class J final;
Spring不是解决了循环依赖问题吗?为什么后面还会报循环依赖的异常?
- ✅
Spring解决的是“属性注入级别的循环依赖”(@Autowired之类的),使用三级缓存解决,因为三级缓存解决的是:✅ “对象已经实例化,但属性还没注入完成”- ❌ 但不允许“
depends-on级别的循环依赖”(@DependsOn("b")之类的),而depends-on的语义是:✅ “当前Bean必须等依赖Bean完全初始化完成”- Spring可以解决的循环依赖有边界:
- 可以解决:
- 单例 + 非构造器 + 属性注入
- 不能解决:
- ❌ 构造器循环
- ❌ prototype 循环、
- ❌ depends-on 循环
dependentBeanMap和dependenciesForBeanMap两个作用对比
Map 作用 主要用途 dependentBeanMap从“被依赖者”找“依赖者” ✅ 销毁顺序(Spring 销毁单例时是逆序销毁) ✅ 循环检测 ✅ 查找“谁依赖我” dependenciesForBeanMap从“依赖者”找“被依赖者” ✅ 销毁时删除边 ✅ 查找“我依赖谁” ✅ 图一致性维护 自定义
Scope有什么特殊性?
自定义
scope的语义不是Spring单例池能直接决定的比如:
2
3
4
5
6
7
8
9
同一次 HTTP 请求内复用;
不同请求创建不同对象;
request scope 对象应该存在 request attributes 中。
session scope:
同一个 Session 内复用;
不同 Session 创建不同对象;
session scope 对象应该存在 session attributes 中。
Spring维护的scopes的Map中会有啥?
request->RequestScopesession->SessionScopeapplication->ServletContextScopewebsocket->WebSocketScope自定义
Scope明明不是prototype,为什么调用beforePrototypeCreation?
- 对于
Spring单例池来说,自定义scope Bean也不是singleton- 它没有
singleton那套创建中标记和三级缓存机制,它不放在singletonObjects,也不走getSingleton(beanName, ObjectFactory)- 因此
Spring借用prototype的创建标记机制,记录当前线程正在创建这个非singleton Bean。主要用于检测循环创建问题。创建成功后进行类型适配,类型是谁指定的?
- 用户显式指定,比如:
UserService userService = applicationContext.getBean("userService", UserService.class);- Spring内部推断,比如:
@Autowired private UserService userService;
创建Bean:AbstractAutowireCapableBeanFactory.doCreateBean()
涉及类
流程图
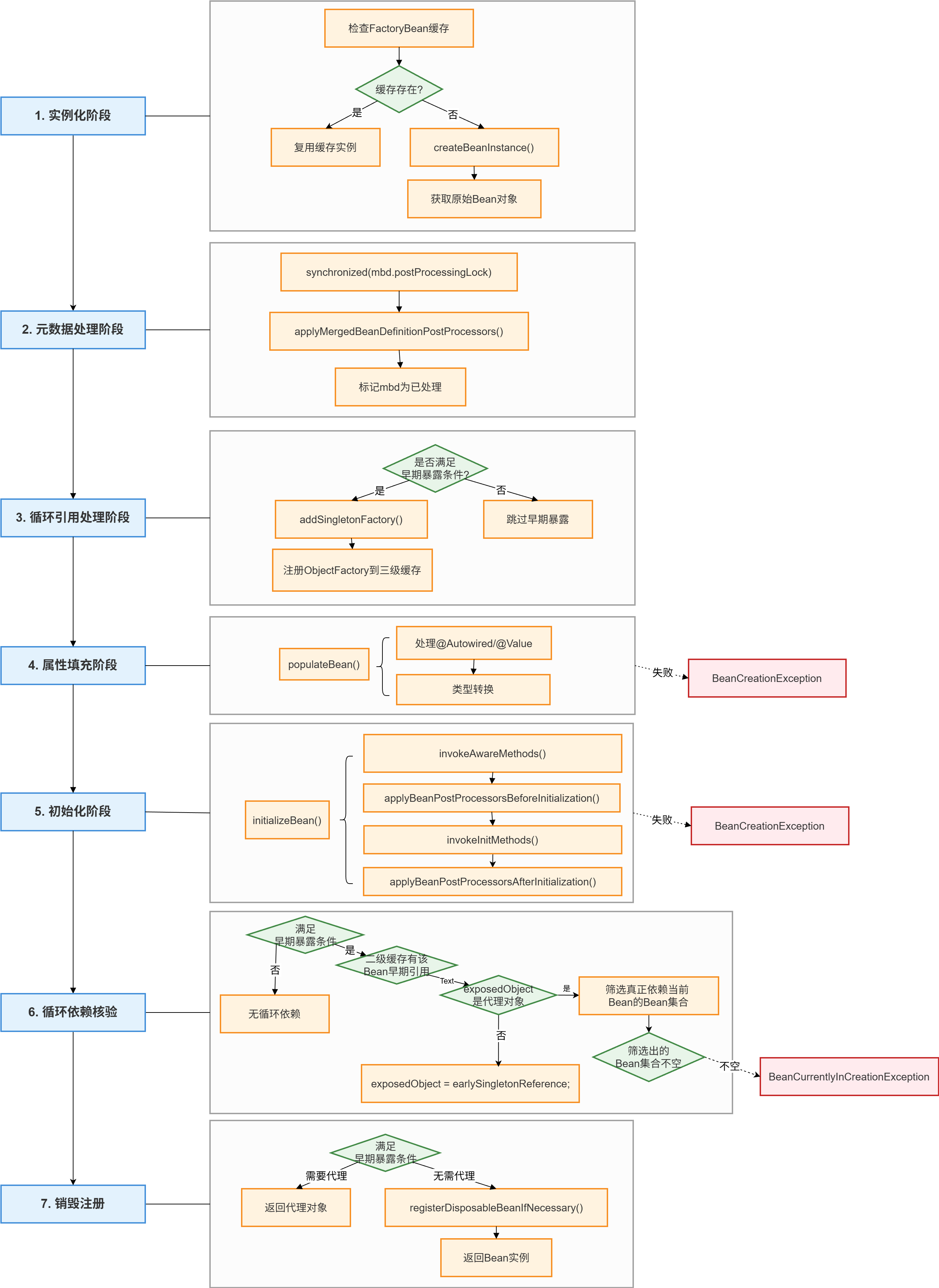
源码理解
1 | /** |
思考
- 为什么
FactoryBean在doCreateBean()中一开始还要尝试从缓存中获取instanceWrapper
- 正式进入
doCreateBean()之前,常常就需要围绕 FactoryBean 本身 做一些额外分析,例如:推断它的类型、决定构造器选择、判断后续产品对象相关语义,因此,Spring 可能会提前为 FactoryBean 本身 创建并缓存一个BeanWrapper,等真正进入doCreateBean()时直接复用。- 这里名字虽然叫
factoryBeanInstanceCache,但它缓存的是FactoryBean本身的BeanWrapper- 普通
Bean通常直接实例化就够了,流程简单,没必要专门走一套额外缓存。
- 在属性填充时,
Spring使用BeanWrapper而不是直接传递Bean实例的设计原因
- 装饰器模式:
BeanWrapper包装Bean实例,增强功能- 反射:直接
Bean无类型转换,而BeanWrapper内置PropertyEditor体系- 嵌套属性:直接
Bean无法处理,而BeanWrapper支持getPropertyValue("user.name")- 元数据:
BeanWrapper保留属性编辑器的注册信息
- 二级缓存在什么时候加入
Bean的早期引用的
- 在获取引用时,依次从一级、二级、三级中查找,如果查找到了三级缓存,并且找到了,则会在找到后将其加入二级缓存,从三级缓存移除(详见上面
getSingleton())
exposedObject = earlySingletonReference;如果是代理状态,不应该是同一个代理对象吗
- 二级缓存中的早期引用
earlySingletonReference有可能在更早阶段就已经被“提前代理”了,而initializeBean(...)之后的exposedObject却仍然只是原始对象。
- 也有可能这两个都是代理对象,但是不同的代理对象,并不同步,
exposedObject来自正常初始化后的最终结果,而earlySingletonReference来自二级缓存中的早期引用,它可能早在三级缓存工厂被调用时就已经被提前代理了。正因为这两个阶段可能不一致
- 如果当前 Bean 是
FactoryBean,注册销毁时注册的是谁
FactoryBean本身,因为当前doCreateBean()创建和初始化的对象就是FactoryBean自己,而FactoryBean#getObject()生产出来的产品对象,不是在这一步注册销毁的。产品对象的销毁要看后续获取与缓存管理逻辑,尤其是单例产品对象时,会在 FactoryBean 相关分支中处理。
doCreateBean()对FactoryBean的处理是否只针对FactoryBean自身?如果是,为什么分析这个方法时还要特别关注FactoryBean#getObject()
单看
doCreateBean(),这个方法负责的是当前BeanDefinition对应实例的创建、属性填充、初始化、循环依赖处理和销毁注册;如果这个实例是FactoryBean,那这里处理的就是FactoryBean本体,不是它的产品对象。之所以还要特别注意
getObject(),是因为doGetBean还会通过getObjectForBeanInstance()等逻辑判断:最终返回给调用方的是FactoryBean本身,还是它通过getObject()生产的产品对象。