安装环境
安装顺序:
- 检查硬件驱动支持的cuda版本
nvidia-smi - 安装cuda(一种通用的并行计算平台和编程模型,由 NVIDIA 开发)(可跳过)
(一般可以直接从第三步开始,因为cudatoolkit的安装包中包含了 CUDA 驱动程序和其他与 CUDA 相关的组件)
一般而言,cuda是向下兼容的,但是不绝对(见下述常见错误2)
- 安装cudatoolkit
- 它包含了 CUDA 编译器、CUDA 运行时库、CUDA 驱动程序等,为开发和运行 CUDA 程序提供基础。CUDA Toolkit 提供了 GPU 计算的基础设施和接口,并包含了与硬件交互的驱动程序。
- 安装cudnn( NVIDIA 提供的一个针对深度学习的 GPU 加速库)
- 安装pytorch(和cuda有对应关系,pytorch发布时会说明cuda的版本要求,二者版本要是配)
方式一:本地安装
在windows中,cuda或者cudatoolkit安装时候是exe文件安装,cudnn是压缩包或者exe可执行程序
按照版本对应关系安装完后,其中cuda是需要在系统环境变量中添加变量的
方式二:在Anaconda的创建的虚拟环境中安装
安装上述库的时候可以指定版本
常见错误
错误1
报错如下:
1 | Solving environment: failed with initial frozen solve. Retrying with flexible solve. |
解释:
这通常是指一个软件包管理器(如pip、conda等)在尝试安装某个软件包时遇到了问题,并且在第一次尝试使用’frozen solve”方法时失败了。
“Frozen solve”是一种求解器的方法,它会尝试使用已知的软件包版本和其依赖项版本来解决软件包之间的冲突。但是,如果冻结的版本之间存在冲突,求解器就无法找到解决方案,就会导致失败。
因此,软件包管理器会自动切换到l”flexible sove”方法,这种方法会更加灵活,可以在软件包的版本之间进行权衡,以找到一个可行的解决方案。这可能需要更长的时间和计算资源,但通常可以解决冲突并成功安装所需的软件包。
解决:
不用管,继续等待即可
错误2
报错如下:
1 | UserWarning: |
解释:
具有CUDA功能的笔记本GPU sm_86与当前PyTorch不兼容”
三种可能原因
- 显卡与CUDA版本不对应
- CUDA版本与pytorch版本不对应
- 三者都不对应
解决:
首先牢记:GPU>CUDA>Pytorch(就是说显卡越好,需要的CUDA版本要越高。
换种说法就是算力越强,CUDA版本。比如3060计算能力为8.6,但是CUDA10.×的计算能力最大为7.5,则就会出现GPU和CUDA不匹配的问题。
GPU算力查询:CUDA GPUs - Compute Capability | NVIDIA Developer
CUDA算力支持查询:CUDA - Wikipedia
错误3
报错如下:
1 | raise RuntimeError('Attempting to deserialize object on a CUDA ' |
解释:
安装的pytorch版本默认安装的是cpu版本,所以用不了gpu
解决
方法1(推荐,通过轮子安装pytorch)
- 在安装torch之前按照下法安装torch
- 去download.pytorch.org/whl/torch_stable.html下载gpu版本的对应版本的轮子
- 本地进入到该轮子所在目录,在cmd中进入到对应的conda虚拟环境中,执行
pip install 轮子 - 解决成功
方法2
检测如下(但不绝对,有些人就没有显示cpu版本,但还是报错用不了gpu版本):
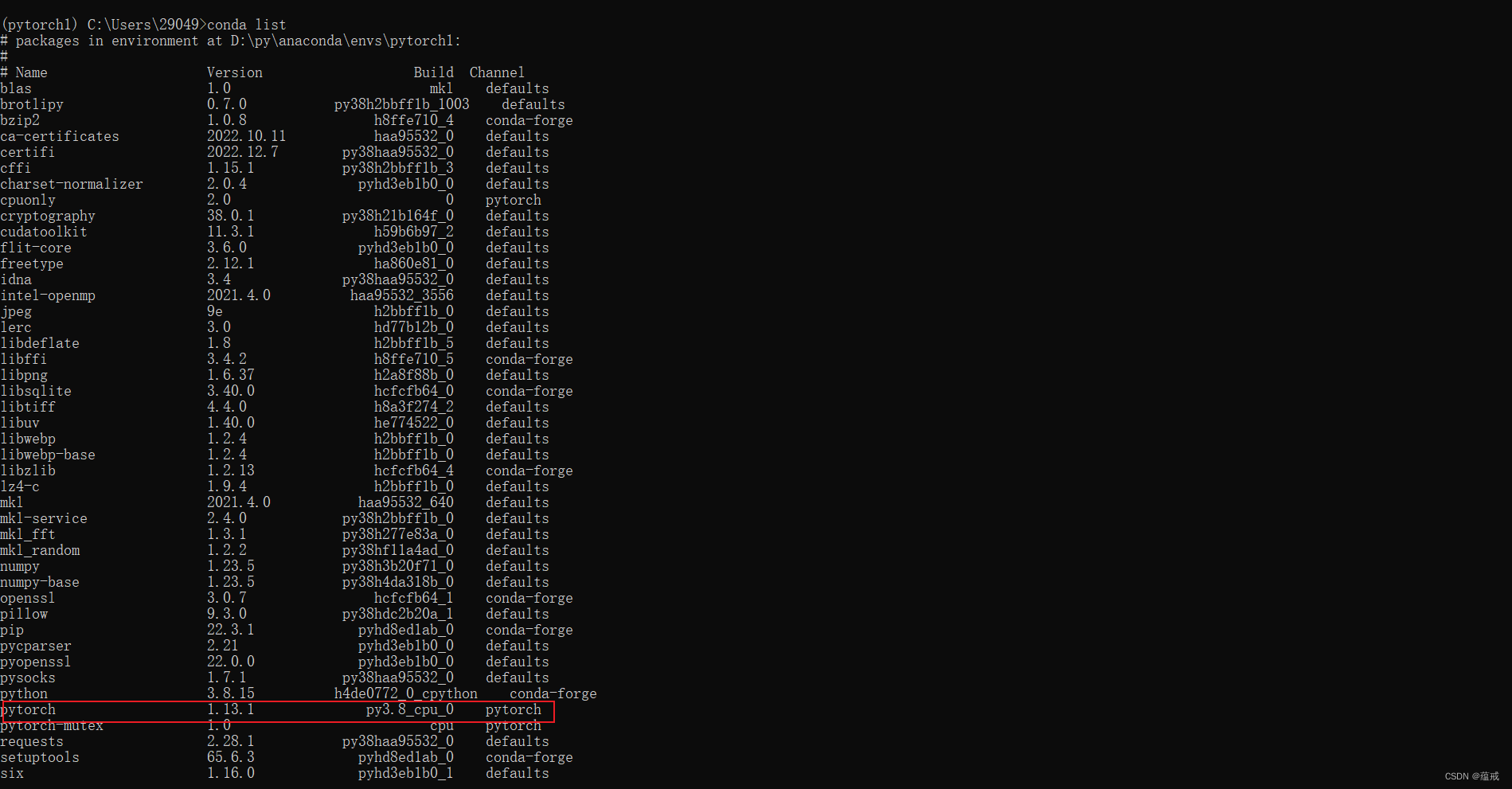
- 如果发现列表中有
cpuonly依赖,则直接到下一步,否则执行conda install cpuonly - 执行
conda uninstall cpuonly - 解决成功,cpu版本转为了gpu版本
conda环境移植
思路:先导出环境配置文件、依赖包信息,然后到目标计算机中使用该配置文件创建新的环境
1 | conda env export --no-builds > environment.yml // 添加 --no-builds 参数,可以防止构建信息包含在生成的环境文件中,从而减少等号的数量。 |
1 | conda env create -f environment.yml // 在新环境中创建环境 |
使用TensorBoard数据可视化
安装依赖
1 | pip install tensorboard |
使用
将模型生成的日志数据整理一下,然后需要写入
tensorboard专门的日志目录中(会自动生成专门的日志文件,内部是字节数据)- 原始的日志数据内容如下,待提取数据,从而写入
tensorboard对应的日志中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import tensorflow as tf
log_file = './log/log_train_epoch.txt' # 输入你的原始的日志文件路径
log_dir = './log/logs' # 输入你的TensorBoard日志目录路径(会自动在内部生成字节型的日志文件)
# 创建一个写入器(Writer)来将数据写入TensorBoard日志文件
writer = tf.summary.create_file_writer(log_dir)
with open(log_file, 'r') as file:
for line in file:
# 解析每行的数据
data = line.strip().split()
epoch = int(data[0].split('Epoch')[1])
time = float(data[1].split('Time:')[1].replace('s', ''))
loss = float(data[3].split('Loss:')[1])
xent = float(data[4].split('Xent:')[1])
htri = float(data[5].split('Htri:')[1])
div_loss = float(data[6].split('div_loss:')[1])
accuracy = float(data[7].split('Acc:')[1].replace('%', ''))
# 将数据写入TensorBoard日志文件
with writer.as_default():
tf.summary.scalar("Epoch", epoch, step=epoch)
tf.summary.scalar("Time", time, step=epoch)
tf.summary.scalar("Loss", loss, step=epoch)
tf.summary.scalar("Xent", xent, step=epoch)
tf.summary.scalar("Htri", htri, step=epoch)
tf.summary.scalar("div_loss", div_loss, step=epoch)
tf.summary.scalar("Accuracy", accuracy, step=epoch)
# 关闭写入器
writer.close()- 生成的
tensorboard对应的日志文件如下: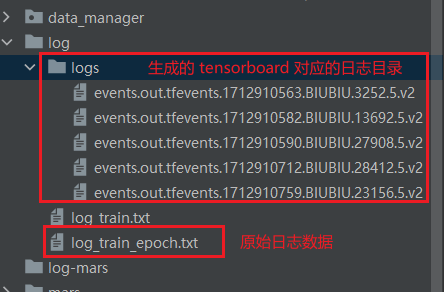
- 原始的日志数据内容如下,待提取数据,从而写入
使用
tensorboard的cmd命令,使用日志文件生成图片网页1
2
3
4# 在命令行终端,输入tensorboard命令进行可视化
tensorboard --logdir=日志文件存放的目录
# 例:日志文件存放在log文件夹下,则写法如下
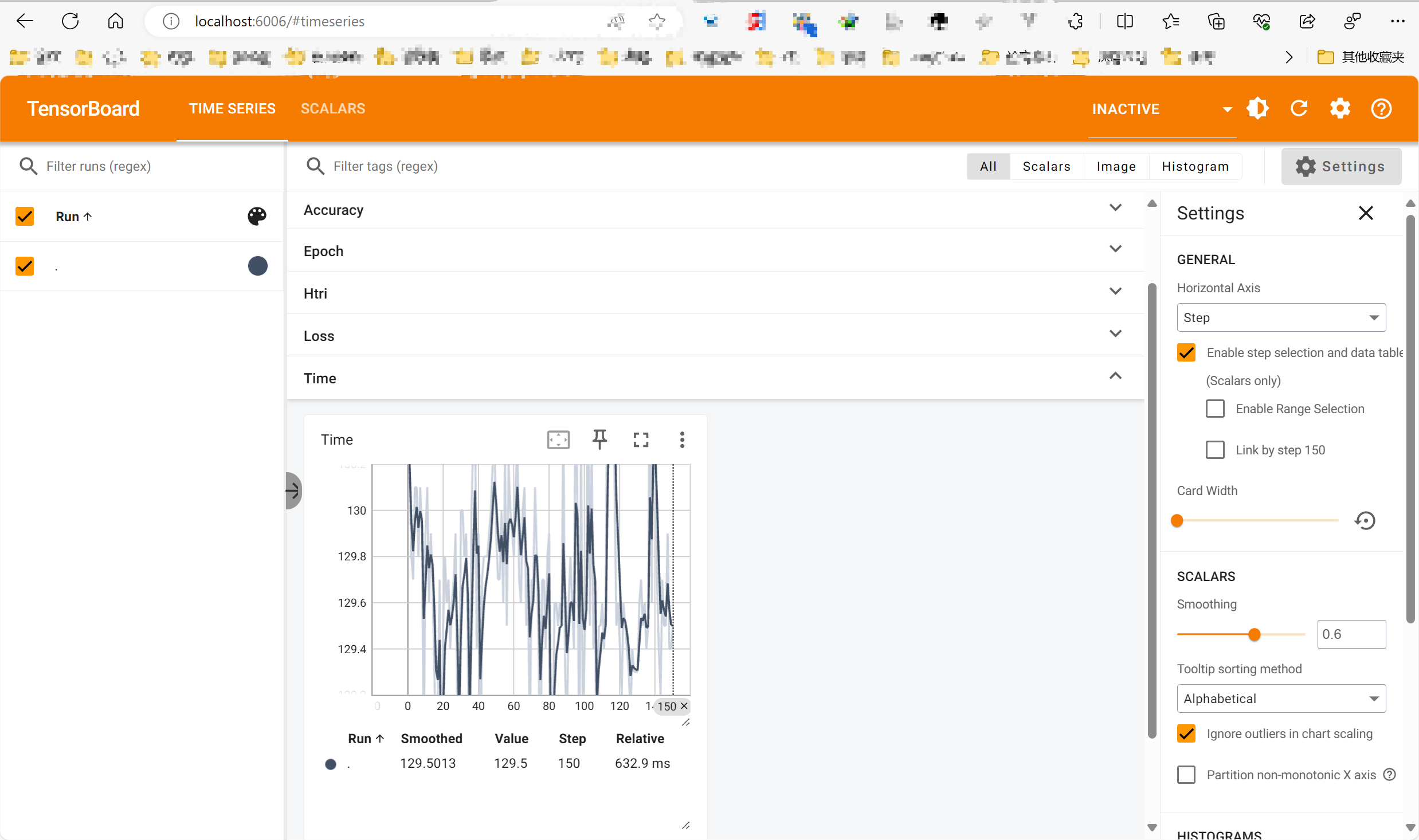
tensorboard --logdir=./log- 执行效果如下:

- 执行效果如下:
常见错误
错误1
报错如下:
1 | AttributeError: module 'numpy' has no attribute 'object'. |
解释:
Since version 1.24 of numpy, np.object is deprecated, and needs to be replaced with object (cf. numpy release notes).
就是说1.24以后版本的numpy,np.object 废弃了,如果需要使用,需要降低版本
解决:
numpy版本降低,我降到了1.23.5后,就成功运行了,效果如下图:
VSCode关闭后,服务器进程保持运行
场景
VSCode连接远程服务器,跑了一个进程,由于需要关闭VSCode,导致进程也终止了。
解决
可以使用如下命令
1 | nohup python webapp.py & |
解释
nohup: 这是一个命令,表示在后台运行命令并忽略挂断信号(SIGHUP)。它允许命令在终端关闭或用户注销后继续执行。python train.py: 这是您要在后台运行的命令。它指示系统运行名为train.py的 Python 脚本。您可以将其替换为您要运行的实际脚本的名称和路径。&: 这是一个特殊的符号,表示将命令放入后台运行。它允许您在执行命令后继续使用终端,而不必等待命令完成。(不加则会占用终端,但是终端不打印信息)
可以使用ps -ef | grep python来查看后台运行的进程,或者使用tail -f nohup.out来查看输出日志。