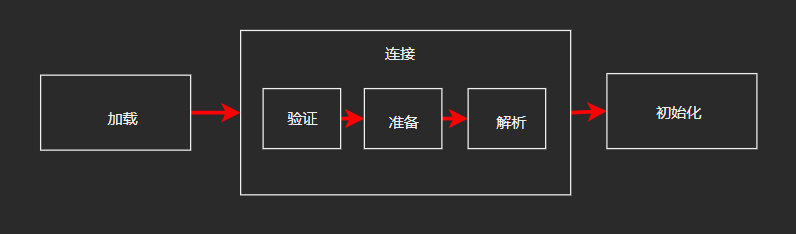
java执行类的阶段划分
jvm在执行某个类的时候,必须经过加载、连接、初始化,而连接又包括验证、准备、解析三个阶段。
常量池分类
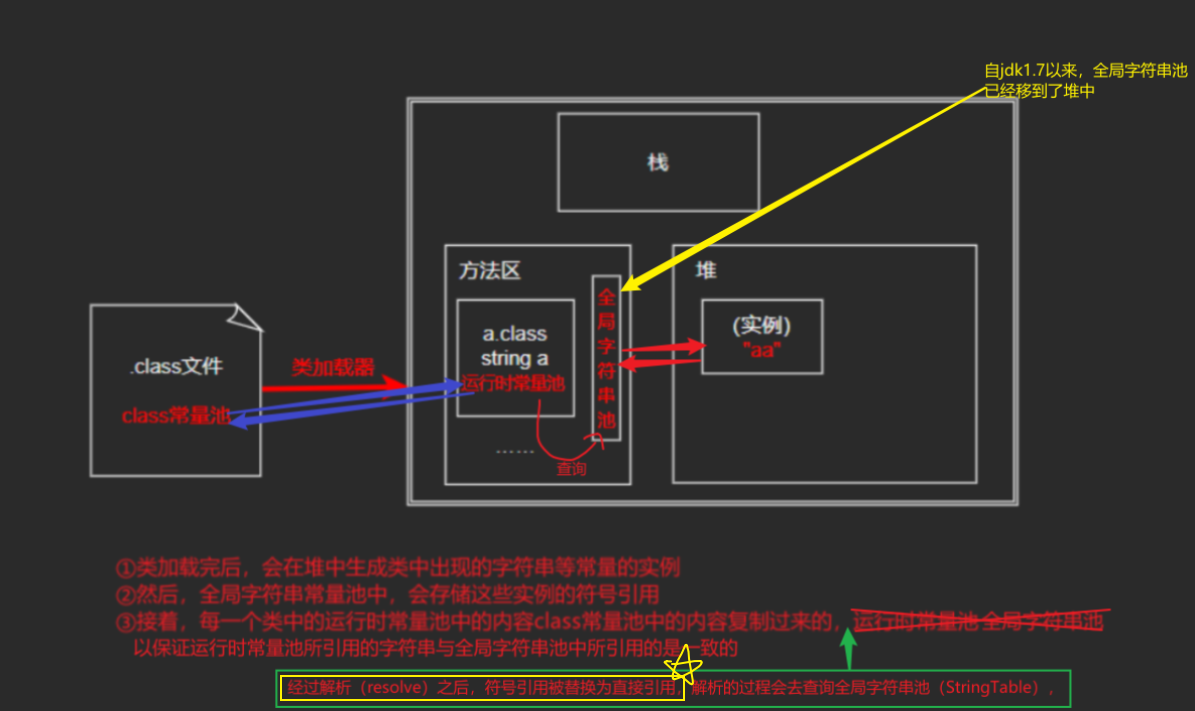
常量池可分为三类:class文件常量池、运行时常量池、全局字符串池
- class文件常量池(class constant pool):
- 出现时间:在类加载之前就存在于class文件中了
- 存放内容:对象的符号引用值
- 存放在class文件中
- class常量池中存放的是字面量和符号引用,也就是说它们存的不是对象的实例,而是对象的符号引用值
- 运行时常量池(runtime constant pool):通常所说的常量池,指的就是运行时常量池
- 出现时间:在类加载之后
- 存放内容:对象的符号引用值,经过解析阶段后,替换为直接引用
- 在class文件被加载进了内存之后,常量池保存在了方法区中,所以,每一个类都有一个运行时常量池
- 在class文件加载之后,jvm就会将class常量池中的符号引用解析后,替换为直接引用,存放到运行时常量池中(也就是符号引用)
- 全局字符串池(String pool或者String literal poll):
- 出现时间:在准备阶段之后(因为解析阶段运行时常量池需要查询全局字符串)
- 存放内容:驻留字符串的引用
- 在类加载完成,经过验证,准备阶段之后,在堆中生成字符串对象实例之后,再将该字符串对象实例的引用值存到string pool中。
- string pool的功能由谁实现?由StringTable类实现,它是一个哈希表,里面存的是驻留字符串的引用,可以依据它找到堆中的字符串实例
- 这个StringTable在每个htoSpot VM 的实例只有一份,也就是说它被所有的类共享
- ==在jdk1.7版本以后,字符串池已经不在方法区,移到了堆中了==
案例
1 | String str1 = "abc"; |
上面的例子虽然简单,但是,几种情况都已经囊括在内了
分析第一句
1 | String str1 = "abc"; |
这一句,在类加载完成后,首先,会在堆中生成一个“abc”实例;然后全局StringTable中存放着“abc”的引用值
分析第二句(注意点)
1 | String str2 = new String("def"); |
这一句,在类加载完成后,首先,会在堆中生成一个“def”实例;然后全局StringTable中存放着“def”的引用值;接着,new 出来一个”def“的实例(这两个实例不是同一个);
生成了两个对象实例!!!
生成了两个对象实例!!!
生成了两个对象实例!!!
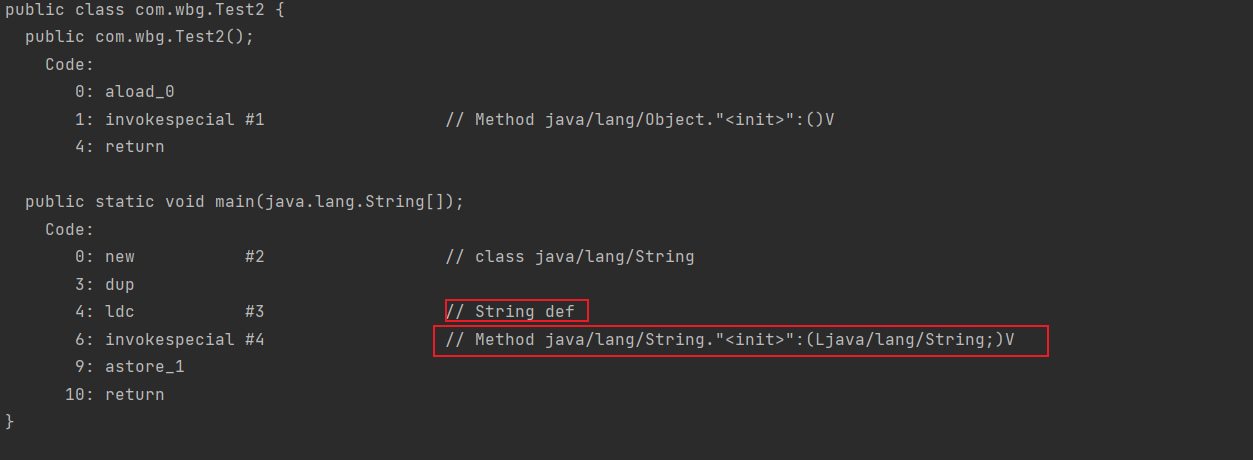
反编译后可以看到,该语句产生了两个实例
重点:new出来的字符串实例,和在全局字符串值中对应的那个字符串实例,是不同的实例
分析第三句
1 | String str3 = "abc"; |
这一句,在类加载完成后,进行解析,会在StringTable里面找到”abc”的全局驻留字符串引用,所以str3的引用地址与之前的那个已存在的相同
分析第四句(关键是intern函数)
1 | String str4 = str2.intern(); |
这一句,在类加载完成后,str4是在运行的时候调用**intern()函数**,返回StringTable中”def”的引用值,如果没有就将str2的引用值添加进去,在这里,StringTable中已经有了”def”的引用值了,所以返回上面在new str2的时候添加到StringTable中的 “def”引用值
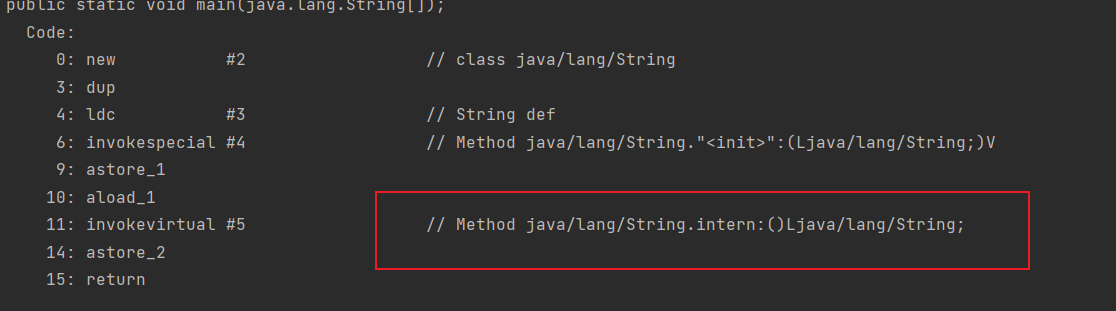
分析反编译后的代码,可以看到,该语句并没有生成新的字符串对象
分析第五句
1 | String str5 = "def"; |
这一句,在类加载完成后,在这里,由于StringTable中已经有了”def”的引用值了,所以返回上面在new str2的时候添加到StringTable中的 “def”引用值
分析第六句
1 | String str6 = "def"+"ine"; |
javac编译器会在编译过程进行一个常量折叠(Constant Folding)的代码优化。经过代码优化之后,这句编译结果是String str6 = "define";
同时,这一句的def和ine不会进到字符串常量池中判断有无,是否需要添加进字符串常量池;
而是只判断一下define是否需要添加进字符串常量池中
总结
java的常量池主要有这么几个内容:
- class常量池:①在编译后就有 ②存储的是对象的符号引用
- 全局字符串池:①在准备阶段后、解析阶段前出现 ②存储的是驻留字符串的引用 ③运行时常量池在解析阶段,要进行查询,确保两个常量池的引用时一致的
- 运行时常量池:显示class常量池中的引用,解析阶段后替换为对象的直接引用
应用
1 | public static void main(String[] args) { |
在上述例子中,得出一下结论:
①直接用引号的(可以有+号进行连接),内容也一样的,引用的就是一个对象
②如果出现类似String c = b + "a";这样的,那么就是在堆中生成了一个新的对象。
补充①:常量折叠和字符串的“+”运算符重载
今天偶然间看到了韩顺平老师在B站讲String的特性的课程,看完后,忽然间觉得自己这块瞬间好像明朗了
(上面的内容虽然也差不多,但总觉得还是繁琐,好像有哪些地方不透彻)
主要是补充对于下面这一句代码的理解(根据韩顺平老师将它底层分析的理解):
1 | String a = "a"; |
不知道为什么韩老师的在调试的时候能够step into进去查看底层执行情况,而我的就不行
但是不影响理解它
显然执行过下面两句后,在字符串常量池中,分别存储了两个字符串:“a”,“b”
1 | String a = "a"; |
然后正片开始!
接下来执行:String ab = a + b;
其实,这句在底层做了很多事情。
- 先创建了一个空的StringBuilder的对象,这个对象是存储在堆中的(先暂时存储一下字符串数据,主要要使用它的append方法)
- 然后先向其中追加了“a”(使用的是它的append方法)
- 然后又向其中追加了“b”(使用的还是它的append方法)
- 然后执行了(且返回给ab)
return new String(value,0,count)(value指的是上面的StringBuilder对象),这样在字符串常量池中就有了“ab”了,同时堆中也new了一个String类型的对象(值就是value中的数据),并且ab就是指向了这个String类型的对象(不是字符串常量池中的)——(这里和是上面的分析第二句是一样的原理)
补充②:String的split()方法
String 类的 split 方法返回的是一个 String 数组,其中的元素是新的字符串对象,并不是复用的字符串常量池中的字符。